
In this blog post, we discuss several important techniques to consider when conducting and analyzing an experiment. They are summarized in the table below and next we discuss each one in a bit more detail. Some of these techniques are bit more advanced (e.g. Blocking, Covariates), but they are introduced here.
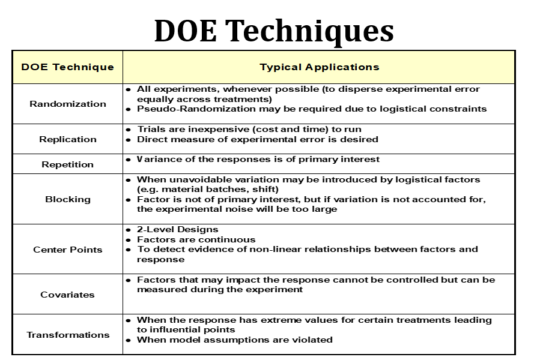
Randomization
Whenever possible, it is recommended to randomize the order of the trials in the study. We want to avoid a bunch of consecutive treatments where the factor levels are not changing. For example, consider the test matrix below that is ordered in the “standard order”.

Notice how X4 is set “low” for 8 treatments followed by “high” for 8 treatments. But what if we can only perform 8 treatments in a day. Now, Factor X4 is always low on day 1 and always high on day 2. If something else changed between day 1 and day 2 (that we were not aware of) and it impacted the response, we would attribute the change in the response to factor X4 changing. We say that X4 is confounded with the Day. Similarly, X3 is confounded with the shift. If a response is correlated with changes in shift and factor X3, how will we know which one caused the response change? Randomizing allows us to disperse the experimental error (discussed in a prior blog) across all the treatments equally.
In same cases, practical constraints prevent complete randomization. For example, there may be a very difficult-to-change factor in the study. So, we do our best to randomize within the logistical constraints and recognize the risks when we cannot do complete randomization.
Replication
Replication means that we perform the experiment treatments again. So, the whole experimental matrix is completed and then we start again and go through the setups again. The experiment may be replicated once or more times. Why would we do this? One key reason is that replicating gives us a direct way to estimate the experimental error in the study. Because we return to the same setup later on, we have provided an opportunity for uncontrolled sources of variation to occur and we can assess the variation that is present between the replicates of each specific treatment. Another reason is to increase the degrees of freedom in the analysis which makes our statistical tests a more sensitive to detect changes in the response. As we increase the sample size, we have a greater chance of observing significant effects. Said another way, the statistical power increases. However, very often replication is not possible (or necessary) and there are other ways to estimate experimental error without replication. Replication is strongly recommended in the optimization phase of experimentation.
Repetition
Not to be confused with Replication, Repetition involves taking multiple response measurements once a specific treatment is set up. The primary reason for repetition is to obtain multiple values so that the standard deviation of the responses (within a setup) can be calculated. This is necessary when the response is a variation response. If our goal is to hit a target value and minimize variation, then repetitions are necessary to calculate a variance response. It may be tempting to perform repetition and treat them as replicates to save the setup time, but this is big mistake since the variation within a single setup does not really capture the experimental error.
Blocking
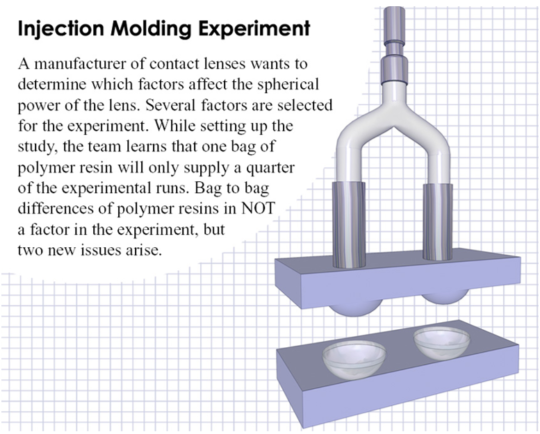
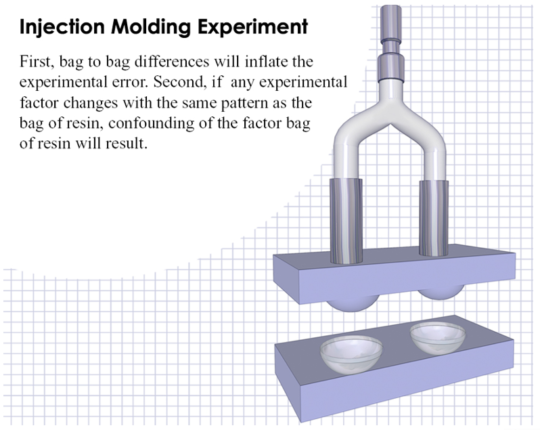
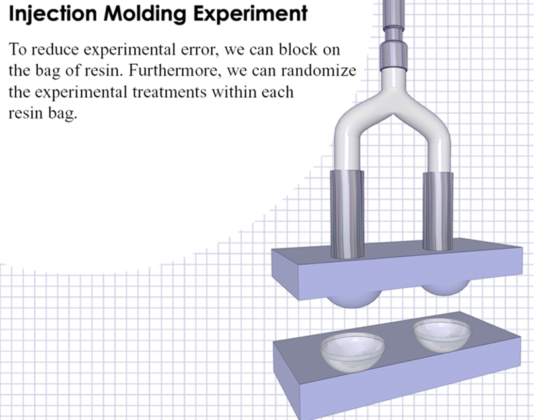
Blocking is a useful technique when certain “nuisance” variables cannot be avoided. Perhaps you are doing an injection molding experiment and you only have enough material in a batch to perform half of the study. The second half of the study must use material form a different batch. The concern is that batch-to-batch variation may impact the results by inflating the experimental error. This could end up masking significant factors if the error is too large. We can introduce a blocking factor which keeps track of the batch in this case. The key difference in the analysis is that the analysis is performed within each set (block) of treatments for each batch and then the results are combined. If in fact there are differences between blocks, it will not affect the error and thus, our results. The cost of blocking is an additional special type of factor and fewer degrees of freedom left for the analysis. Of course, there is a limit to how many blocking factors one can include as we must be able to essentially understand the effects within each block of treatments.
Center Points
When performing screening studies where we normally limit the number of levels for each factor to two, it is a very good idea to use center points. If all the factors are continuous there will only be one center point which is a treatment where all the factors are set halfway between the high level and low level. You can also replicate just the center point, which gives us a cheap way to understand the experimental error based on how similar the results are at the different center point treatments. If one or more factors are categorical, then more than one center points will be needed since there will be no center between a factor that is categorical. We will have what are often termed “face centered” center points. For example, if the factor is material type (A vs B), then there is nothing in the middle of these two choices.Center points are illustrated in the graphics below. Another advantage of center points is that they can give us a clue as to whether nonlinearities in the relationship of at least one the factors and the response is present.
Covariates
In some experiments, it may not be possible to control all the factors that are not being purposely varied in the study. Perhaps the humidity varies throughout the day and we believe it could affect the response. In this case, it is a good practice to simply measure and record the value of this variable while we are performing each treatment in the study. This extra variable can be added to the model if it in fact explains a significant amount of the variation in the response.
Transformations
When analyzing data from an experiment, it may be necessary to transform the responses before developing the predictive model. When certain experimental combinations (treatments) produce a response that is much larger or smaller than the rest of the responses, the variation can overwhelm the analysis by producing large experimental errors. We have seen this on leak rate experiments where a specific treatment will result in a “flood”. A common transformation is a log transform (or natural log transform) which will adjust all the responses but have a bigger effect on the larger numbers. This is a valid approach since the factors that minimize the response will also minimize the log of the response.
Summary
The above techniques should be considered when designing, conducting, and analyzing an experiment. Their proper use requires some experience.